引入注意力机制,亚马逊棋bot神经网络架构再颠覆
引入注意力机制,亚马逊棋bot神经网络架构再颠覆
Wang YinXi最近在折腾 亚马逊棋 的 AI 实现。一路摸爬滚打下来,最大的感悟是:这个游戏的难点并不在于蒙特卡洛树搜索(MCTS)本身,而在于其动作空间(Action Space)的结构极其特殊。
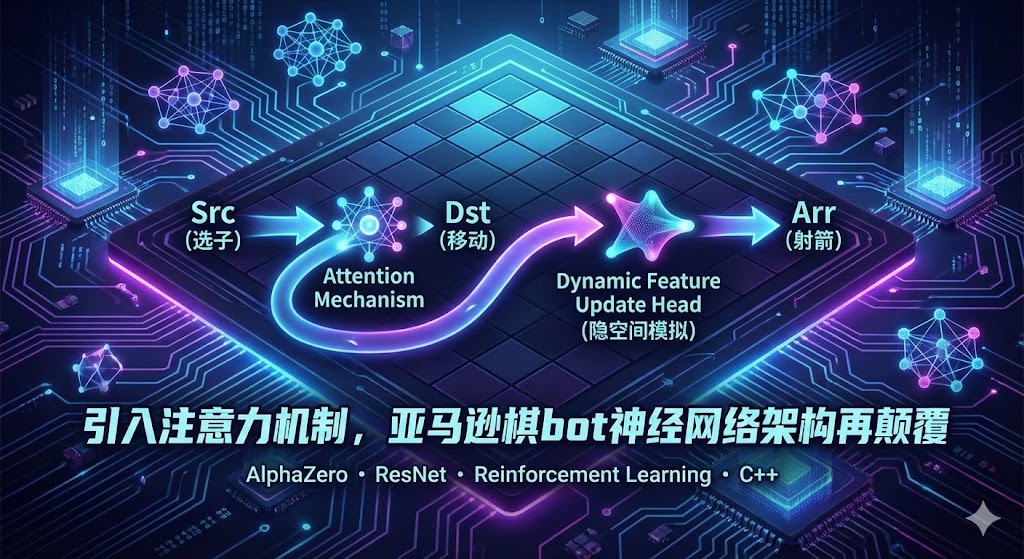
亚马逊棋的一步合法动作由三个强耦合的部分组成:选子 (Src) $\rightarrow$ 移动 (Dst) $\rightarrow$ 射箭 (Arr)。这是一个天然的因果链条。然而,许多基于 AlphaZero 的开源实现为了图省事,往往将其强行拆解为三个独立的分类任务。
这种“扁平化”的处理方式切断了动作间的逻辑联系,导致神经网络难以学到高水平的策略。这篇文章将复盘我是如何引入注意力机制与动态特征更新头,将一个普通的分类网络改造成具备“一次推理、内隐模拟、链式建模”能力的因果架构。
1. 困境:为什么传统的做法行不通?
在架构设计的初期,我尝试了两种主流的解决方案,但都撞了墙。
1.1 方案一:扁平化独立输出 (Flat Classification)
这是最直观的做法:让网络同时输出三个向量
$$
P(Src)、P(Dst)、P(Arr)
$$
- 假设:这隐含了一个错误的数学假设,即选子、移动和射箭是相互独立的事件。
- 现实:“选哪只棋子”直接决定了“能移动到哪里”;而“移到哪里”又物理上限制了“能射什么箭”。
- 后果:模型学会了“A点适合做起点”、“B点适合做终点”,但它不知道A和B可能根本连不通。这导致网络输出大量“局部合理但整体非法”的动作,极大浪费了 MCTS 的搜索算力。
1.2 方案二:串行三阶段决策 (Serial 3-Stage)
另一种常见的做法是模拟人类的步骤:先跑一次网络预测 Src,根据 Src 跑第二次预测 Dst,最后跑第三次预测 Arr。
- 缺陷 A:推理效率低。每走一步棋要运行三次神经网络 Forward,在 Botzone 等有严格时间限制(如 6秒/步)的环境下,这几乎是判了死刑。
- 缺陷 B:决策短视。网络在第一步“选子”时,并不知道这一步走完后能不能射出一支好箭。这种割裂的决策过程导致 AI 缺乏全局观,容易陷入局部最优。
破局思路: 我需要一个既能一次推理(保证速度),又能保留完整因果链条(保证质量)的架构。
2. 核心突破:Dynamic Feature Update Head
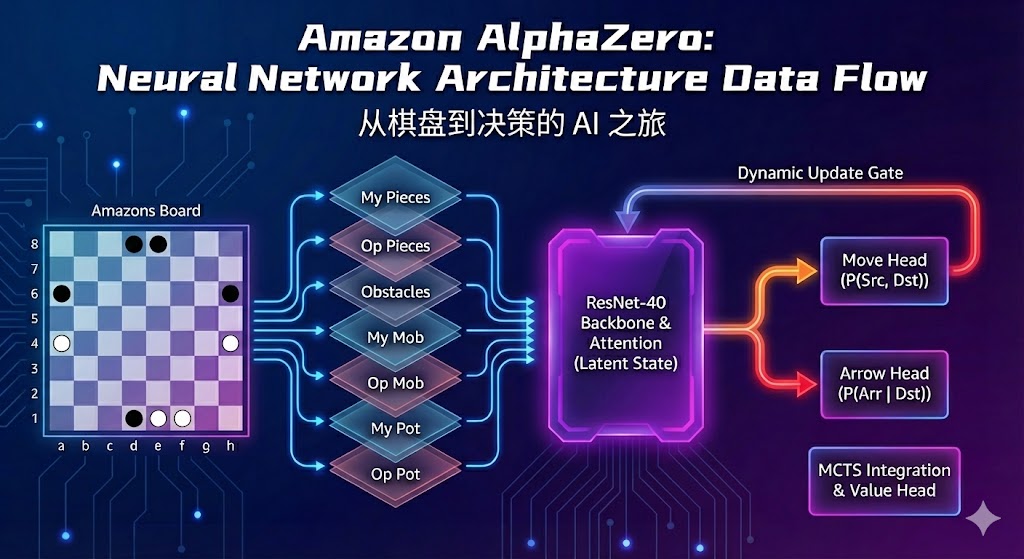
为了解决上述矛盾,我保留了 ResNet-20 作为特征提取的主干(Backbone),但彻底重构了策略头(Policy Head),设计了 Dynamic Feature Update Head。
这个新的 Head 通过三个逻辑步骤,在一次 Forward Pass 中完成了复杂的因果推理:
2.1 第一步:引入注意力机制,预测移动联合分布
我们不再分别预测起点和终点,而是利用 Self-Attention 的思想,计算两者之间的相关性矩阵。
- Query: 起点特征 (Src)
- Key: 终点特征 (Dst)
- Operation:
这样网络直接输出一个 $64 \times 64$ 的联合概率矩阵。网络不再是“乱点鸳鸯谱”,而是学会了特定的起止点组合 (Combo)。非法移动(如被阻挡的路径)在矩阵中会被天然抑制。
2.2 第二步:隐空间内的“思维模拟” (Latent Simulation)
这是本次架构升级的灵魂。在决定了“移动”之后,我们不需要在物理棋盘上更新状态(那需要 CPU 介入,太慢),而是在特征图层面进行了一次模拟。
我们将选定的 Dst 信息注入到当前的特征图中,通过一个 update_gate 卷积层,推演出“假设棋子移动到那里后,局面会变成什么样”。
1 | # 核心逻辑伪代码 |
这一步让网络在隐空间(Latent Space)里真正地进行了一次推演。
2.3 第三步:基于模拟结果的条件射箭
有了 x_next(模拟后的局面感),预测 Arr 就变成了条件概率 $P(Arr | Dst)$ 的计算:
- 网络此时已经“知道”棋子移动到了新位置。
- 它可以基于这个新位置,判断哪些射箭点是合法的、有威胁的。
最终公式:
$$
P(Src, Dst, Arr) = P(Src, Dst) \times P(Arr | Dst)
$$
这种架构不仅在逻辑上闭环,而且将原本割裂的决策整合成了一个端到端的微分过程。
3. 燃料升级:7-Channel 高阶特征工程
架构升级后,还需要喂给它更高质量的数据。为了让网络不仅“看”到棋盘,还能“读懂”局势,我在输入端引入了基于 C++ 引擎位运算逻辑预计算的高阶特征,构成了 7 个输入通道:
- 基础层 (Channels 0-2):
- Ch 0: 我方棋子 (Self)
- Ch 1: 敌方棋子 (Opponent)
- Ch 2: 全局障碍 (All Obstacles) —— 包含敌我棋子及所有的箭。让卷积层直观感知“不可逾越”的区域。
- 机动层 (Channels 3-4):
- Ch 3: 我方一步可达 (My Mobility) —— 假如不射箭,我的棋子能走到哪里。
- Ch 4: 敌方一步可达 (Opp Mobility)
- 意义:直接告诉网络当前的“活动空间”和“控制权”。
- 潜力层 (Channels 5-6):
- Ch 5: 我方射击潜力 (My Shoot Potential) —— 基于 Mobility 再次扩散,表示“我能射到哪里”。
- Ch 6: 敌方射击潜力 (Opp Shoot Potential)
- 意义:这是亚马逊棋最关键的“领地”概念。通过预计算这一层,网络不需要消耗大量层数去学习棋子的“滑步”规则,而是可以直接基于这些特征判断领地的安全性与价值。
5. 总结
这次重构最大的变化不是参数量的堆砌,而是建模思维的转变:
- 从独立到联合:放弃扁平分类,转而对 $Src \rightarrow Dst \rightarrow Arr$ 的因果链进行完整建模。
- 从显式到隐式:用 Feature Update 在隐空间里“模拟移动”,替代了昂贵的物理状态转移。
- 从搜索到直觉:通过 7-Channel 特征和注意力机制,赋予了网络极强的“棋感”,大幅降低了后续搜索的负担。
这就是一个“动作空间巨大,但网络依然能跟上”的高效架构。它不仅解决了亚马逊棋的特有问题,也为处理其他复杂动作空间的游戏提供了一种通用的解题思路。