凤凰涅槃:AlphaZero结构重铸
凤凰涅槃:AlphaZero结构重铸
Wang YinXi🚀 亚马逊棋 AlphaZero:从架构灾难到全链路重铸
——行动空间、数据流、Canonical、网络深度、性能优化,一天内完成 5 个史诗级升级
今天,我们为亚马逊棋(Game of the Amazons)的 AlphaZero 系统完成了一次罕见规模、跨越神经网络 / MCTS / N-to-1 / IPC / C++ 引擎 / 深层模型的 全系统重构。
这篇文章将整合今天的全部内容,从最核心的问题出发,按逻辑顺序讲述:
为何旧系统必然训练失败 → 如何设计空间多头网络 → 如何确保数据不乱 → 如何解决 canonical 冲突 → 如何提升 C++ 与 Python 性能 → 如何构建深度 ResNet-40 全新架构。
1. 动作索引灾难:一切问题的起点
(Action Index Collapse)
旧系统使用 动作索引(action index in legal_moves list)作为策略向量的定义方式,看似简洁,却触发了两个致命的系统性崩溃:
❌ 1. 对称性冲突 → P2 训练崩坏
- getCanonicalForm 会对 P2 棋盘做 180 度旋转
- 但真正的走子代码 Game.getNextState 在“未旋转”的原始状态执行动作
因此:
MCTS 认为“动作 5”是移动 A,但实际执行的是完全不同的动作 B。
结论:
P2 在整个训练过程中相当于在随机乱走 → 胜率统计完全被污染。
这也是我们早期观察到「P2 胜率无脑偏高」的真正原因。
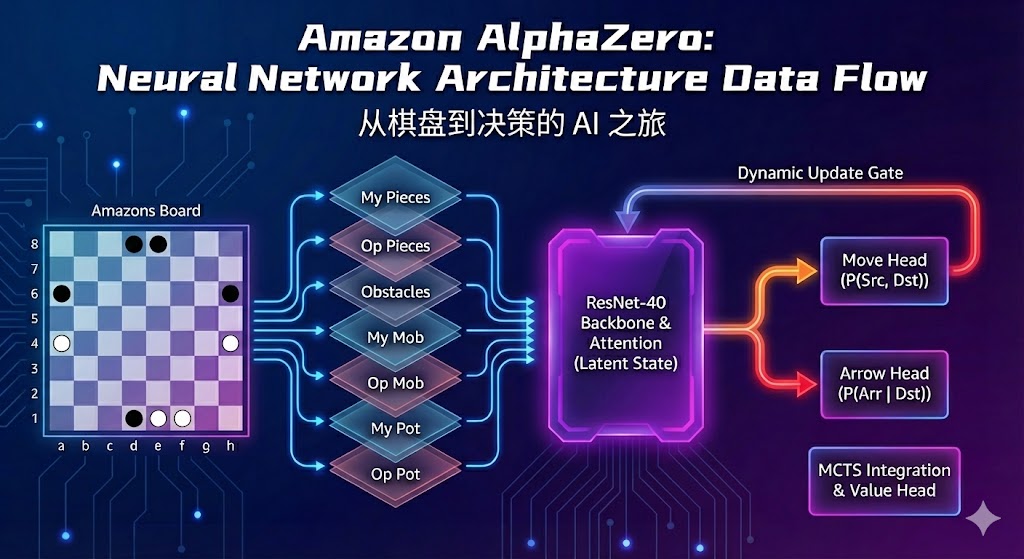
2. 终极解决方案:三头输出的空间式动作建模
(Multi-Head Spatial Policy)
为彻底摆脱 Action Index,我们采用围棋/将棋 AlphaZero 的专业方案:
将动作空间分解为三个 8×8 的空间概率图:
- Source Map:起点位置
- Destination Map:终点位置
- Arrow Map:箭射击位置
这使得动作不再依赖“列表顺序”,而依赖棋盘坐标 → 索引问题彻底消失。
✔ 关键文件修复
| 文件 | 变更 |
|---|---|
| AmazonsPytorch.py | 替换原单输出头为 fc_src / fc_dst / fc_arrow 三头 |
| NNet.py | “正向翻译器”、“逆向翻译器”处理 3 个 8×8 heatmap |
| MCTS & SharedEvaluator | 传输 (3 × 64) 格式的数据而非一个向量 |
| OrchestratedMCTS.py | P = P(src) × P(dst) × P(arr) 组装合法动作概率 |
结论:
神经网络开始学习真正的空间语义,而不是“动态列表顺序”。
3. 训练数据的健壮性重构:
🚫 告别 Action Index → ✔ 引入空间热力图标签
如果最开始的问题是“索引不一致”,那么第二个问题就是“训练数据错位”。
旧系统的训练依赖于:
1 | pi_vector (from MCTS) |
在 N 进程并行、IPC、C++ 状态更新的环境中,这非常容易“错一步就错全局”。
✔ 新系统:训练标签与游戏无关
- MCTS 得到 pi 后
➡ 立即转换为 3 张 8×8 heatmap
➡ 直接存储
➡ 训练时不再调用 C++ 引擎
这样:
- 训练永不可能出现标签错位
- 不依赖游戏引擎
- 无外界状态污染
4. 对称增强的性能革命:
从调用 C++ 8 次 → Numpy 一次旋转即可
旧版 getSymmetries:
- 每次对称增强会 8 次重新初始化 C++ 引擎
- 8 次全盘 getLegalMoves
- 8 次线性搜索 list.index
这是惊人的 O(N) × 8 × 每一步棋 × 每个 Actor 的损耗。
✔ 新版方案:Convert First, Then Rotate
- 用 C++ decode pi → (Src, Dst, Arr) 只一次
- 后续 7 份增强全部使用 Numpy rot90 / fliplr
性能从 O(N) 降为 O(Numpy),快几十倍。
GPU 终于不再等待 CPU。
5. Canonical Form 的统一视角冲突
(最难修的问题之一)
AlphaZero 必须做到:
“无论是白方或黑方,都以统一视角看棋盘”。
也就是说:
P2 必须看到旋转后的棋盘。
但动作也必须跟着旋转。
在新版系统中:
- canonical board:颜色反转 + 180 度旋转
- canonical action → real action:
通过 canonical_to_real_action 完成三点反转
1 | (r, c) → (N - 1 - r, N - 1 - c) |
作用:
- MCTS 始终在 canonical 空间中思考
- 游戏始终在 real 空间中执行
- 两者不再混淆
这是完整分离「思考空间」和「执行空间」的核心。
6. Python / C++ 性能极限优化(Zero-Copy + SHM)——逐步实现
目标:在 32 线程 CPU + RTX 4090 上,把 IPC 与序列化开销降到接近零,使 CPU 用在 MCTS 上,GPU 连续饱和计算。
6.1 问题快照
- Manager().Queue() 的一个消息需要 pickle/serialize/deserialize,且 Manager 为单独进程,会产生锁竞争与上下文切换。
- 频繁 setPieceAt(逐格写入)导致 Python↔C++ 往返多次 syscall / marshalling。
- 大型 NumPy 数组通过队列传输导致 copy(内存与CPU占用)。
6.2 设计思路
- 尽量 零拷贝(zero-copy):Python 端把连续内存块给 C++,C++ 直接读写。
- 队列只传元信息(Actor ID / slot index / shape),实际数据放共享内存(SHM)。
- 高频队列使用
ctx.Queue()(multiprocessing.get_context(‘spawn’) 的原生 Queue),避免 Manager 代理。 - 对关键进程(Dispatcher / GpuWorker)提权,避免被 MCTS 抢占。
- 启动 jitter,避免所有 Actor 同步导致的 sawtooth load。
6.3 实现细节:C++ 批量接口(batchLoadBoard)
C++(建议用 pybind11)——底层接口示例
1 | // amazons_engine.h |
pybind11 导出:
1 |
|
Python 使用要点:
1 | import numpy as np |
要点:绝对不要传非连续数组或错误 dtype —— 会导致 segfault。
6.4 实现细节:共享内存 + 原生 Queue(示例)
Producer(Actor)写入 SHM 并只发 ActorID
1 | from multiprocessing import get_context, shared_memory |
Consumer(Dispatcher / GpuWorker)读取
1 | def worker_loop(): |
关键:消息体很小(整型),数据通过 SHM 直接共享,避免 serialization。
6.5 把 Manager().Queue() 换成 ctx.Queue()、减少锁竞争
Manager().Queue()会走 server/client 模式;ctx.Queue()是 OS pipe/native,延迟低且无需 pickle。- 所有高频通信(Actor→Dispatcher,Dispatcher→GpuWorker)都改为 ctx.Queue()。
6.6 进程提权 & Jitter 启动(示例)
1 | import psutil, os, time, random |
Windows 可使用
psutil.HIGH_PRIORITY_CLASS/psutil.ABOVE_NORMAL_PRIORITY_CLASS。
6.7 避免内存泄漏:mcts.clear_tree()
在 Actor 的每一步棋开始时必须调用:
1 | # 每一步搜索开始前 |
否则 MCTS 树会累积节点,最终导致 Actor 内存占满。
6.8 Batch Size 与 Deadlock 处理
training_batch_size(大,例如 512)用于 GPU 批训练。inference_batch_size(小,例如 16 或 32)用于 Dispatcher 汇总 Actor 的预测请求,减少等待。- Arena 阶段:把 batch 强制降到 4(避免无法凑满导致某些 Actor 无限等待)。
这三者分离能同时保证 GPU 利用率与 MCTS 低延迟。
7. 重铸:ResNet-40(从数据到实现的完整细节)
目标:用 ResNet-40(20 残差块)替换原来只有四层的浅层 CNN,同时把输入改为标准 One-Hot,输出改为三头空间概率(Src / Dst / Arr)。
7.1 输入规范(严格)
对每个棋盘状态,生成 3 通道 one-hot,shape = (3, 8, 8),dtype = float32 或 uint8(训练时转 float32):
- channel 0 — 我的棋子(1 / 0)
- channel 1 — 对手棋子(1 / 0)
- channel 2 — 箭 / 障碍(1 / 0)
示例代码:
1 | def board_to_onehot(board, me=1): |
7.2 ResNet-40 PyTorch 实现骨架(
1 | import torch |
说明:把每个 head 输出的 64 个 logits 做
softmax(或在 loss 中用 log-softmax),训练时分别计算三个交叉熵/kl-loss 并加权求和。
7.3 Loss & Training Pipeline,使用adamW优化器
- 对于每个样本,我们有
target_srcs(64-d one-hot)、target_dsts、target_arrs和v(标量)。 - Loss =
λ1 * CE(p_src, target_src) + λ2 * CE(p_dst, target_dst) + λ3 * CE(p_arr, target_arr) + λv * MSE(v, target_v)。通常λ1=λ2=λ3=1.0, λv=1.0起步。 - 优化器:AdamW(lr 1e-4 ~ 5e-4 视 batch)+ weight_decay(1e-4)常用。
保存/加载 checkpoint(含 optimizer)示例:
1 | torch.save({ |
必须保存 optimizer state,避免 starttrain.py 重启时丢失动量。(忘了说了我为了实现良好的内存管理,循环是又写了一个starttrain.py QAQ ,这样就可以每次结束之后清理所有程序强制释放内存)
7.4 批量与显存调优(RTX 4090)
training_batch_size建议从 256 → 512 尝试(视显存和混合精度而定)。- 强烈建议使用
torch.cuda.amp(混合精度)来提高吞吐。 - Arena/Inference batch 设为 64 或 128(降低 Dispatcher 等待)。
8. Soft Labels(τ=1)与落子策略:完整规则与实现
目标:保留 MCTS 的探索信息到训练数据,避免后期 NN 变成贪心的盲目收敛器。
8.1 基本规则(明确)
训练标签始终使用 MCTS 的访问次数分布(soft labels):
πi=Nivisits∑jNjvisits\pi_i = \frac{N_i^{\text{visits}}}{\sum_j N_j^{\text{visits}}}πi=∑jNjvisitsNivisits
这里
N_i^{visits}是 MCTS 在根节点各动作上的访问次数。将pi解码为三张 heatmap 并存储为训练示例的标签。下棋落子(selfplay 中):
- 在游戏早期(步数 <
temp_threshold,比如 15 步)使用τ=1:按 π 采样动作(保留探索)。 - 当步数 ≥
temp_threshold,切换为τ=0:使用argmax(确定性落子)以保证对局评估稳定。
- 在游戏早期(步数 <
8.2 具体实现(伪代码)
1 | # 在每一步 MCTS 结束后: |
说明:训练时永远不要把 argmax 的 one-hot 作为 pi —— 这会丢失探索信息。
8.3 为什么这重要(更深一点的理由)
- MCTS 的访问分布包含树搜索中探索-回报估计的“软信息”(哪些替代动作经常被访问)。把它作为目标标签可以让 NN 学会“潜在好变的动作倾向”,而不是仅仅学习一个确定性策略。
- 如果使用
argmax作为标签,训练目标会鼓励 NN 立刻收敛到贪心策略,失去后续发现更优策略的能力(过拟合于当前搜索)。
8.4 实际跑实验时的技巧与监控
- 保存 raw visit_counts(或压缩后)便于回溯与 debug。
- 在训练中监控 KL(π_old || π_predicted) 以及 Entropy(π)。如果 KL 快速下降到 0、Entropy 极低,说明标签可能被污染或 τ 策略被误用。
- 训练初期把
temp_threshold调大(例如 30)可获得更多探索样本,后期再逐步缩短。
最终结语:
今天我们完成的不是修补,而是一次彻底重铸。
从底层 C++ 到顶层 ResNet-40 到 MCTS,到 IPC,到数据流,到 canonical,到多头空间策略 ——
这是一个 面向高性能 AlphaZero 系统的完整工程重构。
现在的系统具有:
- 正确动作表达
- 正确 canonical 语义
- 正确训练标签
- 高速无锁 IPC
- Zero-Copy C++ 接口
- ResNet-40 深度模型
- 高效对称增强
- 高质量 MCTS 数据
- 全核满载的训练性能
这是亚马逊棋 AlphaZero 能够真正开始「学习」的起点。