Amazon棋强化学习模型AlphaZero训练
Amazon棋强化学习模型AlphaZero训练
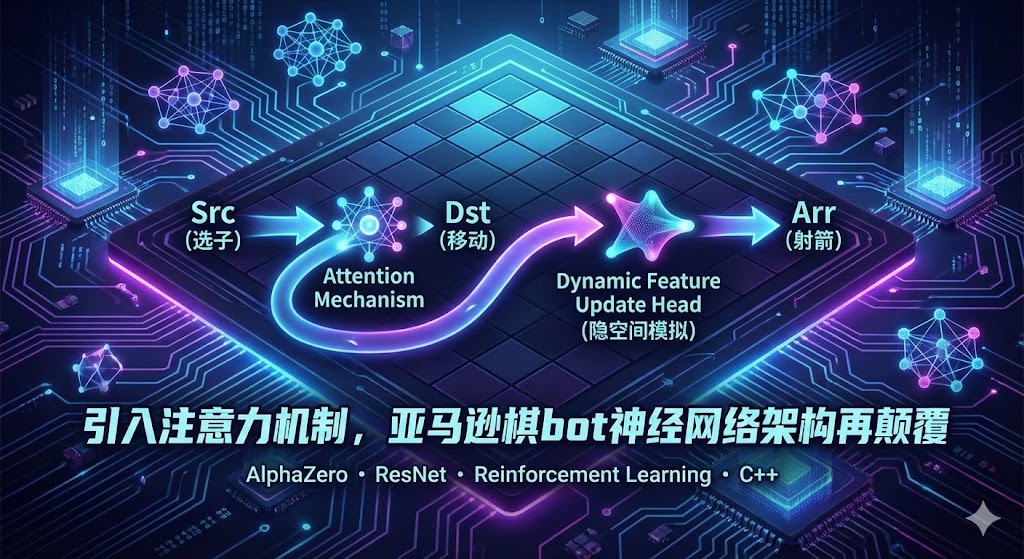
Wang YinXi从0到AlphaZero:我的亚马逊棋AI分布式训练系统演进之路
这学期xk计概大作业是实现一个亚马逊棋(Amazon Chess)的AI。这是一个在10x10棋盘上进行的复杂策略游戏,棋手不仅要移动棋子(像国际象棋的皇后),还要在移动后“射箭”来封锁格子。它的复杂度远超普通棋类。说实话我也不知道老师在期待什么基础路径,而我对于强化学习和ai的热忱促使我再github上找到了开源的alphazero-general模型,由于从小耳濡目染的了解到了alphazero的强大,虽然其未必是作业的最优解,但是过程中的乐趣和积累强化学习经验的意义都是很宝贵的,于是迅速敲定方案。
这个项目从一个简单的C++游戏引擎开始,最终演变成了一个我始料未及的、复杂但高效的分布式训练系统。这篇文章我想分享的,不仅是我的最终成果,更是这个“系统”是如何一步步演化出来的。
虽然我感觉我的技术路径比较难以复刻,但是在交作业之前还是不便开源了,作业结束之后我会上传到github上开源,也会在本文中附上链接。
阶段一:地基——C++核心与Python集成
万丈高楼平地起。项目的第一步是构建一个坚实的地基。
- C++核心引擎:为了追求极致的性能(其实是害怕没有cpp成分不给我过(bushi)),我使用C++编写了核心游戏逻辑 (
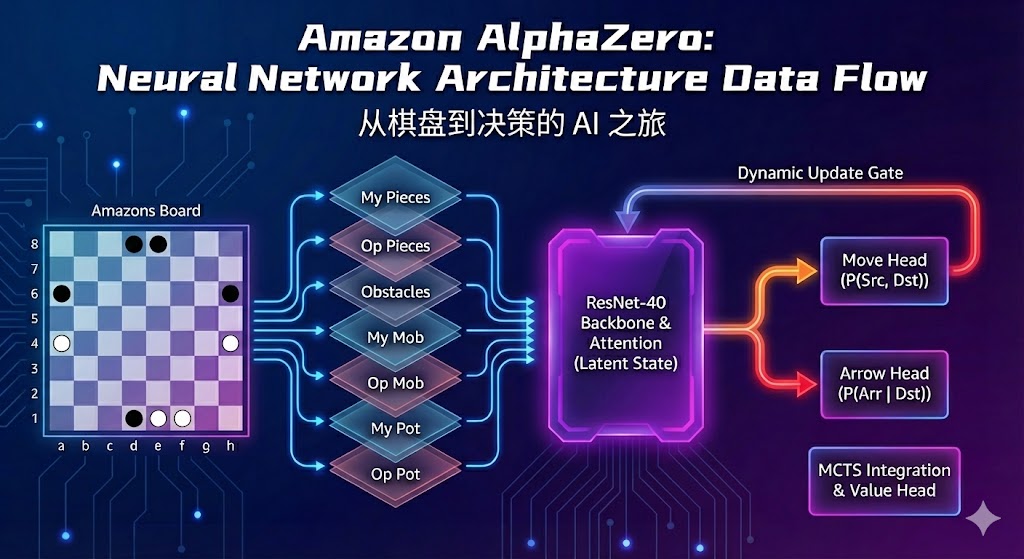
amazoncore.cpp)。这包括了棋盘表示、棋子移动、射箭、路径验证和胜负裁定。 - Pybind11桥接:AlphaZero的训练框架(如PyTorch)是基于Python的。我使用
pybind11创建了一个C++到Python的桥梁 (amazons_engine.cp39-win_amd64.pyd),将底层的游戏引擎暴露给Python。 - AlphaZero框架集成:我编写了
AmazonsGame.py接口文件,将C++引擎“翻译”成AlphaZero通用框架能理解的接口,如getInitBoard,getNextState等。
至此,我有了一个可以运行的基础版本。它可以跑,但仅此而已——在单个线程上,MCTS(蒙特卡洛树搜索)的速度慢得令人绝望。此时我发了pyq吐槽…不过我助教居然看到了还真的指出了有可能的方向..!
阶段二:初探并行——N-to-1架构与瓶颈
AlphaZero的训练(自对弈)天生适合并行。于是,我实现了第一个并行方案:N-to-1架构。
- N个Actor (CPU):我启动了多个并行的MCTS搜索进程(Actor),它们在CPU上运行,各自进行模拟。
- 1个Evaluator (GPU):一个专用的GPU进程,负责接收所有Actor发来的棋盘状态,通过神经网络进行批量评估(返回策略和价值)。
- 1个共享队列:N个Actor通过一个共享队列,把评估请求发给GPU进程。
这个方案在Actor数量较少时工作良好。但当我把Actor数量(比如N=32)/simus数开大,试图榨干CPU性能时,灾难发生了:
瓶颈出现!
共享队列成为了系统的瓶颈。大量的Actor都在疯狂地往队列里塞请求,而GPU进程虽然在拼命处理,但这个“1”还是太慢了。更糟糕的是,CPU上的Actor在发出请求后必须等待GPU返回结果才能继续搜索,导致CPU和GPU的利用率都上不去,双方都在“摸鱼”等对方。
阶段三:架构突破——N-to-M-to-1的诞生
我意识到,Actor的搜索和GPU的评估必须解耦。Actor不应该等待GPU,而GPU也不应该被零散的请求打扰,它应该专注于处理大规模的批处理数据。
受此启发,我设计了全新的 N-to-M-to-1 架构。
我在N个Actor和1个GPU之间,引入了一个新的中间层:M个调度器 (Dispatcher)。
这个系统的流水线如下:
- N个Actor (CPU):只负责MCTS搜索。它们生成评估请求后,不再等待,而是直接把请求丢给“调度器”进程,然后立即开始下一次搜索。
- M个Dispatcher (CPU):它们是“批处理工”。它们从各自的共享队列中收集来自Actor的请求,将其打包成一个优化的数据批次(Batch)。
- 1个GPU Worker (GPU):这是系统唯一的GPU进程,也是“评估核心”。它不直接与Actor通信,而是从M个调度器那里接收“批处理”好的数据,进行高效的神经网络推理,然后将结果原路返回。
这个架构彻底解决了瓶颈:
- 解耦:Actor和GPU Worker被Dispatcher隔开,各自全速运行。
- 吞吐量:通过M个Dispatcher进行批处理,GPU总能收到“喂饱”的大批量数据,GPU利用率飙升。
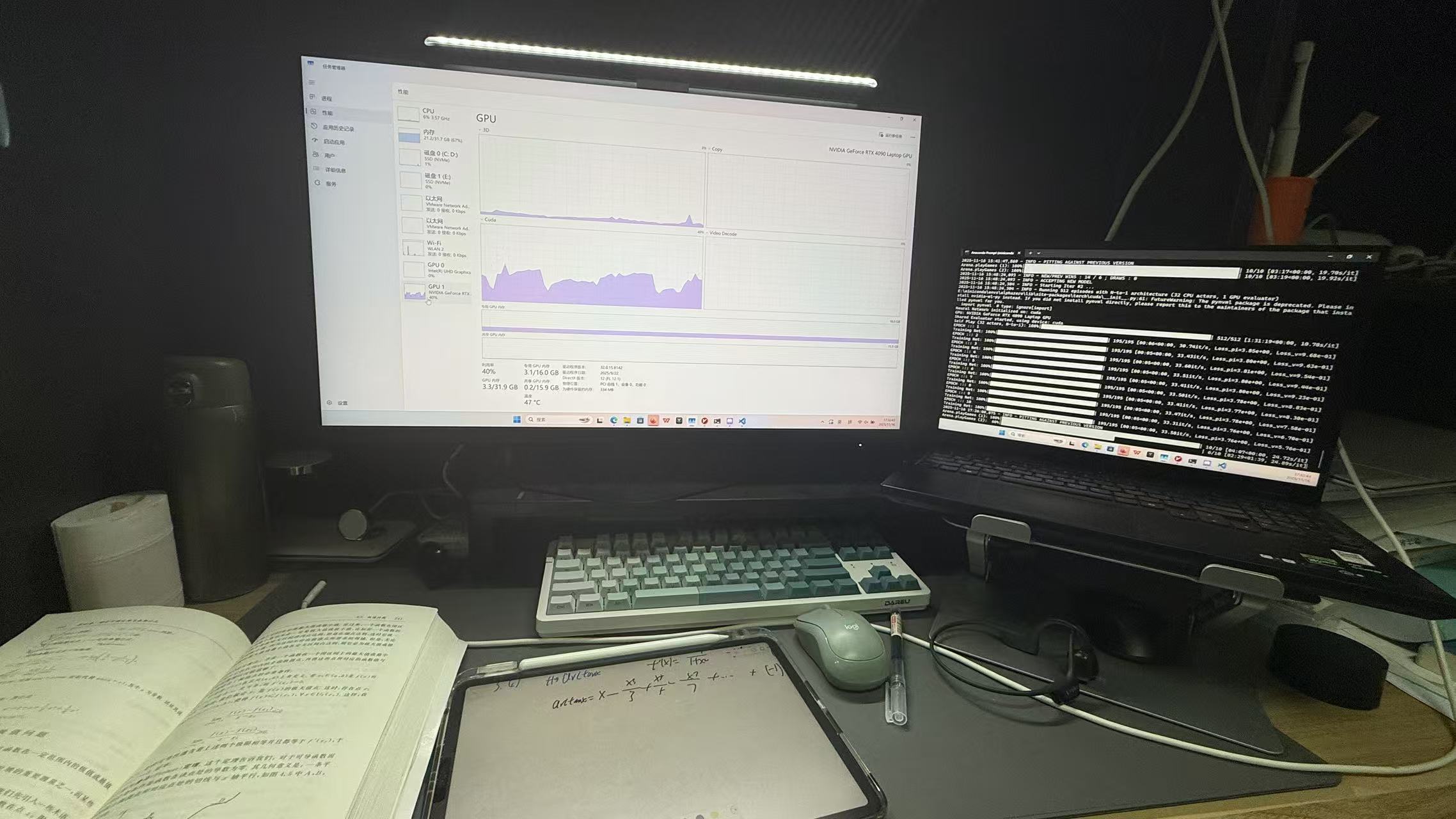
- 扩展性:我可以根据硬件(我是i9 14900hx(12C 32T)CPU配单个4090laptop)自由调整N、M和批处理大小,实现资源利用最大化。(最后参数也暂且不能给你明确答复,乐,自己调参去,我作业结束后会公布)
阶段四:精益求精——“榨干”性能的内存攻坚战
系统能跑了,但能跑得“久”吗?在昨天2025.11.16半夜的半夜训练中,我一早起来发现虽然上一轮跑完了,但是再开启第二轮的时候第一轮的内存几乎没有被释放,我的笔记本只有32G RAM,加上虚拟内存最高占用了80余G,导致内存溢出,训练停止并且任务管理器 状态栏等程序均卡死,电脑时间永远暂停在了早上五点…..
我又开始了新一轮的“攻坚战”:
- MCTS树内存泄漏:我发现MCTS树在回合(Episode)结束后没有被正确释放。经过排查,我修复了逻辑:MCTS树在每“回合”结束后必须重置,在回合内的每“一步”之间也重置,这是无奈之举。
- GPU显存泄漏:这是个更棘手的问题。我发现PyTorch在多进程环境中,张量(Tensor)如果没有被显式删除,即使Python的垃圾回收(GC)启动,VRAM也可能不会被释放。解决方案是,在
GpuWorker.py中,对所有传入和传出的张量添加显式的清理逻辑 (del tensor) 和垃圾回收调用。
在修复了这些问题后,系统终于实现了长时间训练下的稳定内存使用。(?真的吗,还不确定,再跑一晚上试试)
最终成果与总结
经过这四个阶段的演进,这个项目从一个简单的“计概作业”,变成了一个高性能、可扩展的AI训练系统。它不仅具备了高效的N-to-M-to-1训练架构,还包含了一个基于Web的UI仪表板、多种训练配置(--fast, --parallel, --n-to-1等)以及一个高性能的C++核心。
回顾这个过程,我最大的收获是:一个复杂的系统工程,其价值不仅在于最终的实现,更在于识别瓶颈、分析问题和设计架构的迭代过程。
这个项目教会我的,远比“计概A”课程本身要多。